用户名
UID
Email
密码
记住
立即注册
找回密码
只需一步,快速开始
微信扫一扫,快速登录
开启辅助访问
收藏本站
快捷导航
门户
Portal
社区
BBS
资讯
会议
市场
产品
问答
数据
专题
帮助
签到
每日签到
企业联盟
人才基地
独立实验室
产业园区
投资机构
检验科
招标动态
供给发布
同行交流
悬赏任务
共享资源
VIP资源
百科词条
互动话题
导读
动态
广播
淘贴
法规政策
市场营销
创业投资
会议信息
企业新闻
新品介绍
体系交流
注册交流
临床交流
同行交流
技术杂谈
检验杂谈
今日桔说
共享资源
VIP专区
企业联盟
投资机构
产业园区
业务合作
投稿通道
升级会员
联系我们
搜索
搜索
本版
文章
帖子
用户
小桔灯网
»
社区
›
A、行业资讯区
›
同行交流
›
图解大模型计算加速系列:分离式推理架构1,从DistServe ...
图文播报
2026庆【网站十三周
2025庆【网站十二周
2024庆中秋、迎国庆
2024庆【网站十一周
2023庆【网站十周年
2022庆【网站九周年
返回列表
查看:
10963
|
回复:
0
[讨论]
图解大模型计算加速系列:分离式推理架构1,从DistServe谈起
[复制链接]
风云
风云
当前离线
金桔
金币
威望
贡献
回帖
0
精华
在线时间
小时
雷达卡
发表于 2025-1-30 11:47
|
显示全部楼层
|
阅读模式
登陆有奖并可浏览互动!
您需要
登录
才可以下载或查看,没有账号?
立即注册
×
大家好,最近Kimi开源它的推理系统Mooncake的技术报告,让分离式推理架构的关注度一下上升了起来。所以在这个系列中,我打算写一写关于分离式推理架构的一些有趣的优化知识。对于这个架构,我之前也只是了解一些,并没有深入探究过,所以在这个系列中我也和大家一起学习,一起发现好玩的东西。
本篇作为该系列的第一篇,
选择DistServe这个分离式架构入手,选择它的原因是
:
这篇论文中通过各种实验和数学建模,很好论述了“为什么要用分离式架构”这一点。很适合初次了解这个架构的朋友阅读。这也是本文强调的重点
这篇论文代码是开源的,本文在写作时,也借鉴了开源代码的一些内容
调度策略比较简单(FCFS),也没有做抢占之类的操作(所以本文的重点也不会放在这里)
【大模型计算加速系列】
猛猿:图解大模型计算加速系列:FlashAttention V1,从硬件到计算逻辑
猛猿:图解大模型计算加速系列:Flash Attention V2,从原理到并行计算
猛猿:图解Mixtral 8 * 7b推理优化原理与源码实现
猛猿:从啥也不会到CUDA GEMM优化
猛猿:图解大模型计算加速系列之:vLLM核心技术PagedAttention原理
猛猿:图解大模型计算加速系列:vLLM源码解析1,整体架构
猛猿:图解大模型计算加速系列:vLLM源码解析2,调度器策略(Scheduler)
猛猿:图解大模型计算加速系列:vLLM源码解析3,块管理器BlockManager(上篇)
猛猿:图解大模型计算加速系列:vLLM源码解析3,Prefix Caching
(BlockManager下篇)
猛猿:图解大模型计算加速系列:分离式推理架构1,从DistServe谈起
【历史文章汇总】
猛猿:【必看】历史技术文章导航
【如有帮助,欢迎大家点赞收藏和在看~~】
<hr/>
一、LLM推理的两阶段及评价指标
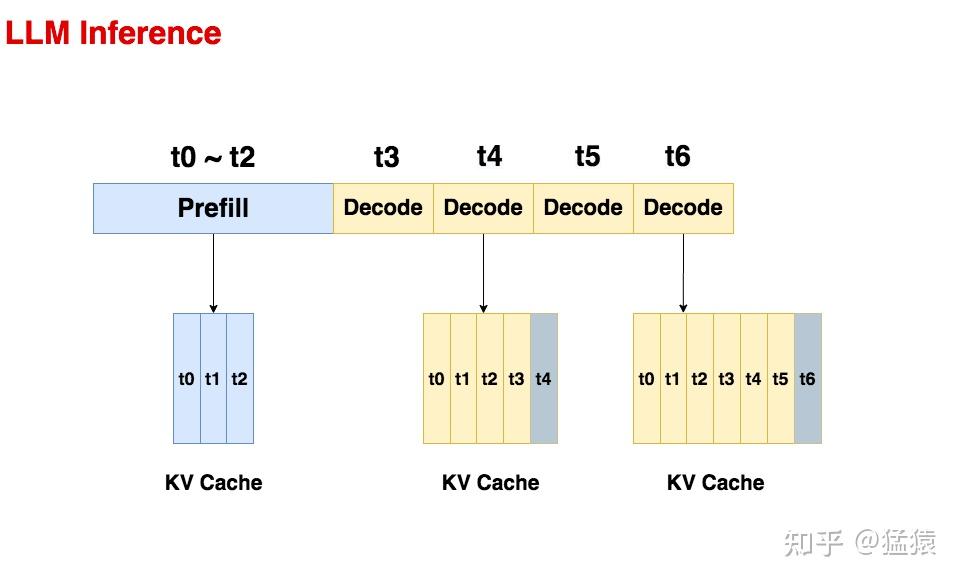
1.1 LLM推理的两阶段
prefill阶段
:把整段prompt喂给模型做forward计算。
prefill阶段结束后,模型产出第一个token
(例如图中t3)
decode阶段
:
一个token一个token地产出response
。(例如图中逐一产出t4,t5,t6)
既然LLM的推理由这两个阶段组成,那么一个LLM系统的性能评估同样也和这两个阶段密切相关。解析来,我们来看两个分别用于评价这两阶段性能的指标。
1.2 prefill性能评估指标:TTFT
TTFT(Time To First Token),表示生成第1个token所用的时间,这是prefill阶段的重要评估指标之一
。
在实践中,我们一般会人为设置一个
TTFT SLO(Service Level Objective)
,这个指标是我们给系统提的要求,只有系统达到了这个指标,我们才认为它的性能达标了。举例来说,
假设我们定P90 TTFT SLO = 0.4s
,那么这意味着我们对该系统的要求是:“90%的request的TTFT值都必须<=0.4”
1.3 decode性能评估指标:TPOT
TPOT(Time Per Output Token),产出每一个response token所用的时间,这是decode阶段的重要评估指标之一
。
同样,
我们也有一个TPOT SLO指标
,这是人为给系统定下的性能要求。
二、为什么需要做prefill和decode分离
在快速回顾LLM推理的两阶段及它们的评估指标后,
现在我们来看一个重要的问题:为什么需要做PD分离?
2.1 分离架构速览
在一些推理框架中,prefill和decode是合并在一起的,你可以通俗理解成一块gpu上我既做prefill又做decode。我们以vllm框架为例:
在一张卡上它的prefill和decode是交替进行的,即vllm的调度器会根据存储使用情况、请求池中的请求状态等要素,决定在模型推理的每1个阶段是做prefill还是做decode。
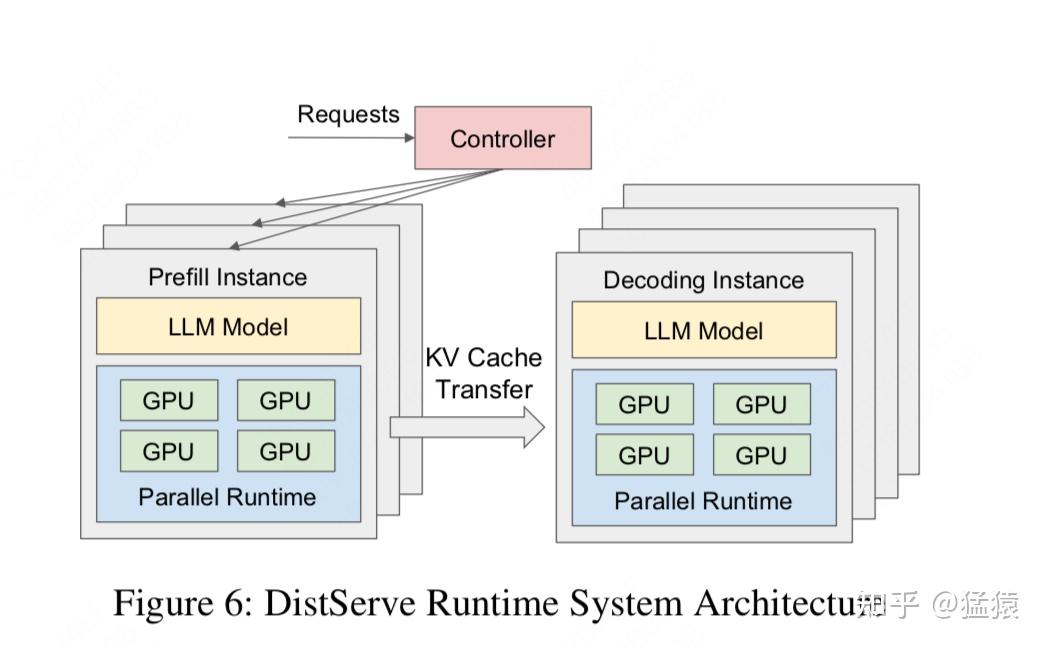
那分离式的框架长什么样呢?我们直接来看DistServe提供的一张架构简图:
从这张架构简图中,
我们不难发现,在分离式框架中prefill和decode不再共享一块/一群gpu,而是你做你的prefill,我做我的decode
。prefill实例计算完毕后,把产出的KV Cache传送到decode实例,然后decode实例继续做推理。这里我们再明确一些术语:
Prefill instance
:
prefill实例
。
一个prefill实例中包含一个完整的模型
,它可能占据1或多块gpu。
Decode instance
:
decode实例
。定义同上,只是它与prefill实例不再共享gpu。
介绍到这里,你肯定开始疑惑了:
从直觉上看,分离式架构相比于合并式架构,多加载了模型副本(耗显存),同时还涉及到gpu间的KV Cache传输(耗时间),怎么看都好像比不上合并式架构,那么我们做分离的原因何在呢?
接下来,我们就来回答这个问题。
2.2 TTFT和TPOT间的balance
假设你现在有一个requests pool,里面装了状态不同的requests,有正在等待做prefill的,也有刚做完prefill等待做decode的,而你面前只有1张GPU。由于prefill和decode在做fwd阶段的差异性,如果不考虑特殊的优化方法,在模型每1个推理阶段,你要么全做prefill,要么全做decode。
现在你需要做一个决策:在下1个推理时刻,我该做prefill,还是做decode?
你观察了一下requests pool,发现里面塞满了等待做prefill的请求,你心想“要不还是赶紧多做些prefill,好歹给用户返回第一个token,防止他们生气了直接不用我的产品了”。所以你在接下来的时刻中一直在做prefill,
由于gpu资源是有限的,你做了prefill就无法同时做decode了,你其实是在牺牲TPOT保全TTFT,反之亦然。
所以这时,你产生了一个疑问:当prefill和decode合并在一起的时候,似乎无论调度策略怎么调整,TTFT和TPOT这两个指标都存在强耦合关系。因此如果我把这两个阶段分开,让TTFT和TPOT各自独立发展优化,会不会得到一个更好的结果?
DistServe做了一个实验来验证你的猜想,接下来我们就来看这个实验结果。
2.3 分离VS合并:一个实验结果
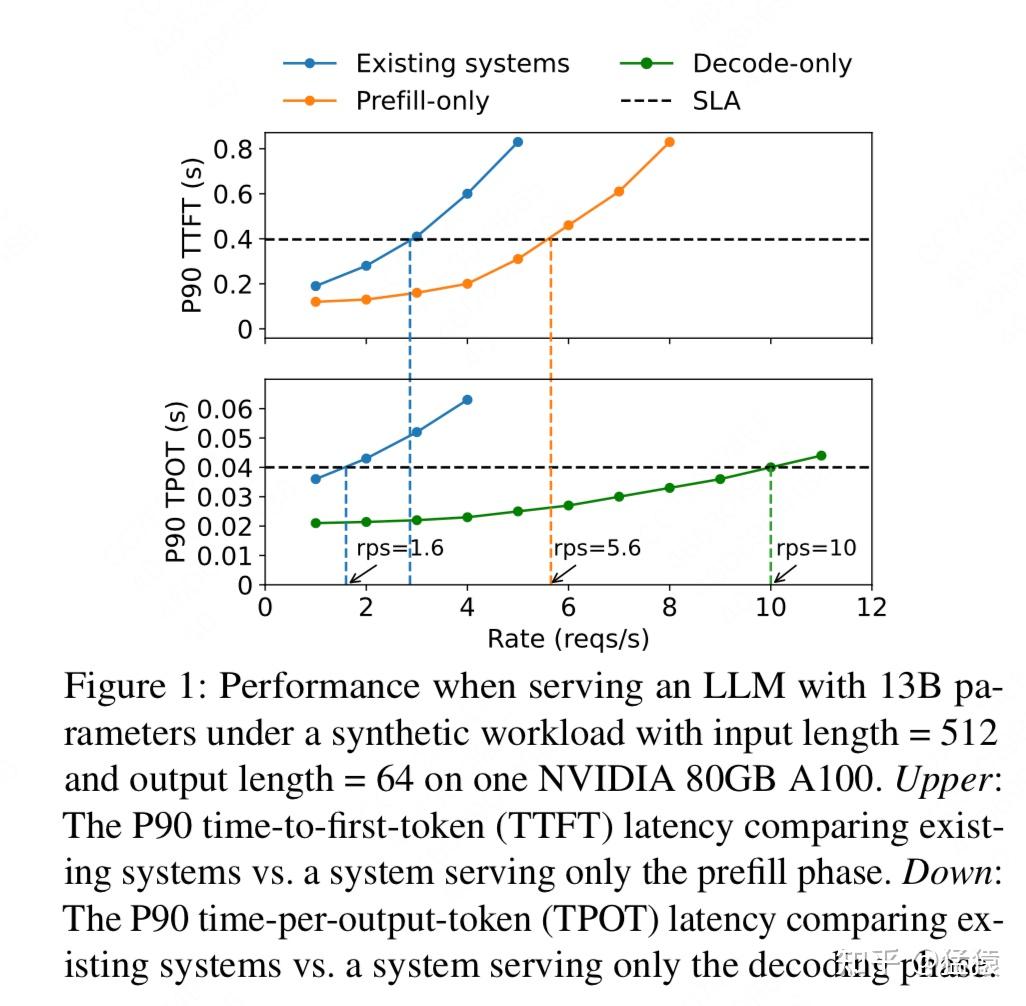
实验配置:
1张A100 80G的gpu
13B LLM,input_length = 512, output_length = 64
SLO(人为定义的系统性能达标要求):
P90 TTFT = 0.4s,人为定义在prefill阶段90%的请求的TTFT必须达到0.4s(上面那张图黑色虚线部分)
P90 TPOT = 0.04s,人为定义在decode阶段90%的请求的TPOT必须达到0.04s(下面那张图的黑色需要部分)
我们先只看图中的蓝线部分:
在蓝线部分对应的实验中,我们采用PD合并的架构
横轴表示每秒到达这块gpu上的请求数量,记为rps(requests per second)
随着rate增加,我们统计每个请求的TTFT和TPOT指标,进而绘制出蓝线。
将蓝线和我们设定的SLO(黑虚线)对比发现,如果我们同时达到设定好的TTFT SLO和TPOT SLO,我们的最大rps = 1.6,我们也记这个指标为goodput。
再来看图中的黄线和绿线部分:
还是这块gpu,现在我们做两次实验,一次实验只让它处理需要做prefill的请求(黄线),一次实验只让它处理需要做decode的请求(绿线)
按照前文介绍的流程,我们得到在这块gpu上只做prefill时,它的goodput=5.6;只做decode时,它的goodput=10。
从这个实验中,我们可以发现,一张卡只做prefill或者只做decode的goodput,都要比它既做prefill又做decode的goodput要高,这也验证了我们前文的猜想:合并式架构可能会同时损害TTFT和TPOT。
假设现在我们不考虑KV cache传输的网络成本
,观察上述实验结果可发现:
纯decode的goodput是纯prefill的goodput的2倍,所以我们可以估算:如果我拿2张卡纯做prefill,1张卡纯做decode,那么我这三卡构成的架构的goodput就为10,也即单卡goodput = 3.3。这是合并式goodput(值为1.6)的2.1倍!
再换一个角度粗糙地看:分离式架构中,我们三张卡承受起了10 reqs/s的流量;而合并式架构中由于单卡流量承受为1.6 reqs/s,所以我们需要6张卡才能承受起10 reqs/s的流量。
因此回到2.1结尾中我们的疑问,乍一看分离式架构似乎更耗卡了,但实际中如果优化得当,它其实是比合并式架构更加省钱的。
三、分离架构下prefill/decode的优化方向
通过上面的分析,我们具象化体会到prefill和decode分离的好处。
在本节中,我们再进一步,详细来看当我们确定可以使用分离架构后,prefill和decode阶段都有哪些优化方向。
3.1 算力与存储的独立优化
prefill阶段:拥有计算受限的性质(compute-bound)
,特别是在请求流量较大,用户的prompt也比较长的情况下。prefill阶段算完KV cache并发给deocde阶段后,理论上prefill就不再需要这个KV cache了(当然你也可以采用LRU等策略对KV cache的保存做管理,而不是一股脑地清除)。
decode阶段
:
拥有存储受限的性质(memory-bound)
,因为token by token的生成方式,decode阶段要频繁从存储中读取KV Cache,同时也意味着它需要尽可能保存KV cache。
对comput-bound和memory-bound不理解的朋友,可以参见我之前的这篇文章(TODO)。
正是由于这两个阶段这两种特性,我们在为其做硬件分配时,也有了更加灵活的空间,而不是只使用一套型号完全一致的硬件。
也就是在分离式框架下,计算和存储可以朝着两个独立的方向做优化
。
3.2 batching策略的独立优化
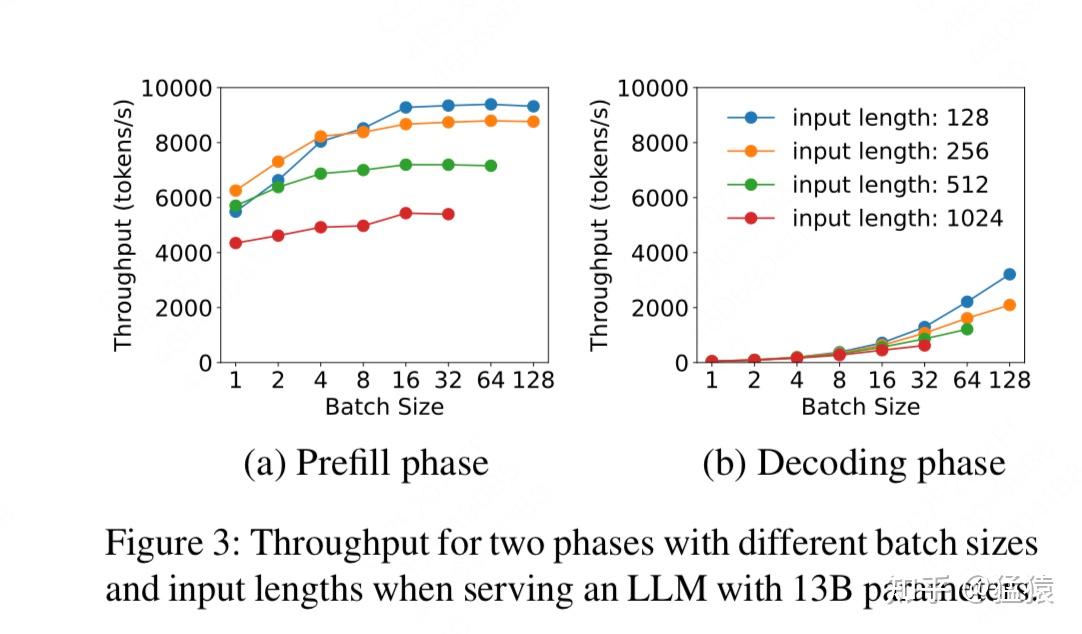
我们依然先展示DistServe所作的一个实验结果。
这个实验比较了在不同batch size下,prefill和decode阶段的吞吐量情况(tokens/s,即每秒能处理的tokens数量)不同颜色的线条代表不同大小的input_length。
prefill阶段
:
随着batch size的增加,吞吐量的增长趋势却趋于平缓
。这正是因为prefill阶段是compute-bound的,当batch中的总tokens数大于一个阈值的时候,prefill阶段产生compute-bound,使得吞吐量的增长趋势变缓(这里我们不考虑显存问题,因为在该实验中硬件显存足够这些不同batchsize和input_length的数据使用)。
decode阶段
:
随着batch size的增加,吞吐量的增长趋势越来越显著
。这是因为decode阶段是memory-bound的,即相比于计算,读写数据的时间要更多。所以在decode阶段中,如果我们能提升batch size,就能把计算强度提起来,吞吐量就上去了。
通过这个实验,我们不难得出结论:prefill和decode不适合用一样的batching策略,所以当两者分离后,我们可以在batching上继续做优化。
3.3 并行策略的优化
在合并式框架中,prefill和decode共享一个模型,这意味着它们共享一样的dp/tp/pp/....等并行策略。考虑2.3中的实验结果,我们根据实验指标,认为可以设计一个
2个prefill实例(dp=2),1个decode实例(dp=1)的分离系统
。所以我们自然而然想到,如果prefill和decode分离了,那是不是意味着它们的并行策略可以各不相同呢?
由于在前面的定义中,我们认为一个prefill/decode实例包含一个完整的模型副本。所以在本节的并行策略中,我们只考虑tp + pp(即1个实例只通过tp +pp划分)
。这样一来,只要对这两个阶段,分别确认好最佳的tp + pp策略,我们就可以用这个策略复制多个prefill/decode实例了(dp维度)
明确了这一点,接下来,我们通过一个有趣的实验 + 数学建模的方式,来看一下prefill和decode在并行策略(tp, pp)上的倾向性。
(1)prefill阶段的并行策略
怎么样可以知道不同并行策略对prefill阶段的影响呢?最简单的方法当然是通过做实验。实验我们肯定是会做的。
但在展示实验结果之前,我们尝试一个有趣的思路:能否拟合一个数学模型,来评估不同并行策略对prefill阶段的TTFT指标的影响?
如果我们能做这样的数学建模,同时用实际实验结果去论证数学模型的有效性
,那么之后我们的系统在选择最佳并行策略时,就不需要通过做实验(比如模拟假数据,送入模型实际做fwd)的方式去搜索最佳的并行策略了。我们完全可以用自己的数学模型去估算一个结果,这样岂不是能降低系统在初始化时的耗时?
在DistServe中,在研究不同并行策略对prefill阶段TTFT的影响时,就使用了“排队论”建立了这个数学模型
。
不过由于这个模型中一些强假设性(我们马上会讲这点),它并没有用在最终的代码实践中(代码实践换了一种建模方式,我们马上也会谈)。不过因为我觉得这个基于排队论的建模挺有意思的,所以我在这节中也会详细来讲。
在下面的讲解中,对于prefill阶段,我们分别对于单卡,2卡pp,2卡tp的情况做基于排队论的建模(
没错,这里我们先不谈tp + pp 的混合情况,这里我们主要想看对于prefill阶段,它对纯tp和纯pp的倾向性)。
单卡下prefill TTFT
我们假设队列中的请求服从排队论中的M/D/1模式
,这个模式的含义如下:
M:请求的到达过程遵从柏松分布
。即请求的到达系统是
相互独立
的(不存在互相干扰)且单位时间内各请求到达系统的概率是
等可能
的。
D:假设所有请求做prefill的处理时间相同
。这个处理时间是指请求被喂给模型一直到模型吐出结果的时间。这就是我们前文说的“强假设”情况。
1
:可以理解成只有1张gpu
在这个模式下,单卡下prefill阶段的avg_TTFT可以被建模成:
D:即前文所说的单个请求处理时间
R:即遵从柏松分布的请求到达率(每s有多少个请求到达gpu)上。
我知道你现在一定对公式(1)一头雾水,不要急,我们这就来详细解释它。想象一下,对于队列中的某个请求,它的TTFT要怎么计算呢?稍一动脑,我们不难从直觉上给出:
一个请求的TTFT = 这个请求在队列中等待的时间 + 单个请求被处理的时间 = 排在这个请求之前的请求数量 * 单个请求被处理的时间 + 单个请求被处理的时间
这里,单个请求被处理的时间 = D,而根据排队论,我们可以从概率论的角度推算出(推导过程略)排在这个请求之前的请求数量 = \frac{RD}{2(1-RD)} 。这样,我们就得到了公式(1)
最后注意,在M/D/1理论的假设下,RD一定是小于1的,如果RD大于1,则意味着这个系统的队列长度会趋向无限(即处理速度比进入速度慢,且进入是不停歇的),那么这时候就不再适合用这个排队理论了。
2-way PP下prefill TTFT
现在,我们假设有两张卡,我们对模型做2-way pp,则此时prefill阶段的TTFT建模如下:
下标inter表示层间切分,在这篇文章里我们都表示成pp
,其余指标基本不变,只是D变了,具体来说有:
D \approx D_{s} \approx 2 * D_{m} 。哦?这是什么意思呢?
D \approx D_{s} :
这个Ds表示这个请求的处理时间
,也还是为这个请求被喂进模型到这个模型吐出相应结果的时间。所以它和D是近似的。
D_{m} :
这个Dm就不太相同了
。想象一下排在这个队列中最前面的两个请求。在单卡情况下,当第一个请求进入模型后,第2个请求需要等待D的时间才能被处理。但是在2-way PP的情况下,第1个请求过完第1张卡,第2个请求就可以跟上了,所以第二个请求理论上的等待时间预估为$$\frac{D}{2$$,这也就是我们的Dm。
再严谨一点,Dm可以认为是pp过程中最慢的那个stage的处理耗时。
2-way tp下prefill TTFT
同样假设有2张卡,做2-way tp,则我们有:
这里的K可理解成是一个折损因子。
理论上,如果不考虑因为tp产生的通讯消耗,那么此时在多个gpu上做不同head的并行计算,可能是比单个gpu同时做这些head的并行计算要快的。
但是如果考虑了通讯消耗,那么这个加速时间就有所折损
,我们设1<K<2。不同的设备拥有不同的折损因子,它对TTFT也是有影响的。
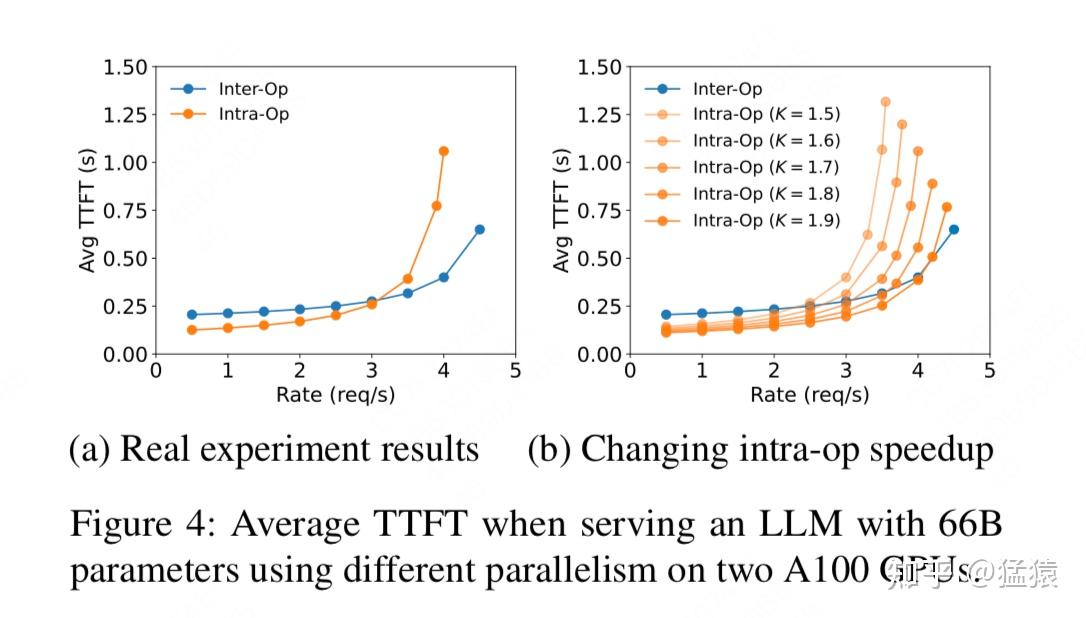
建模 VS 实验结果
建模建完了,这下我们可以用真实的实验结果看看建模拟合效果怎么样了
。在DistServe中,确实做了这样的一个实验,
同时也提到了建模效果基本拟合的试验曲线的趋势(但是没有单独给出建模效果的趋势图)
。我们来看下实验效果:
如图,左侧为真实实验的结果
。关于右侧的图,我这里有些迷惑,它似乎是在论证tp模型中取不同折损因子K值时对TTFT的影响(黄线),但是如果是这样,这个曲线应该是用建模结果表示的,但它现在却长得和真实实验结果一致。
但是anyway,回到左侧的真实实验结果上,我们不难发现,对于prefill阶段,在rate较小时,更适合用tp;在rate较大时,更适合用pp。也即prefill阶段在不同条件下,对并行方式有倾向性
。
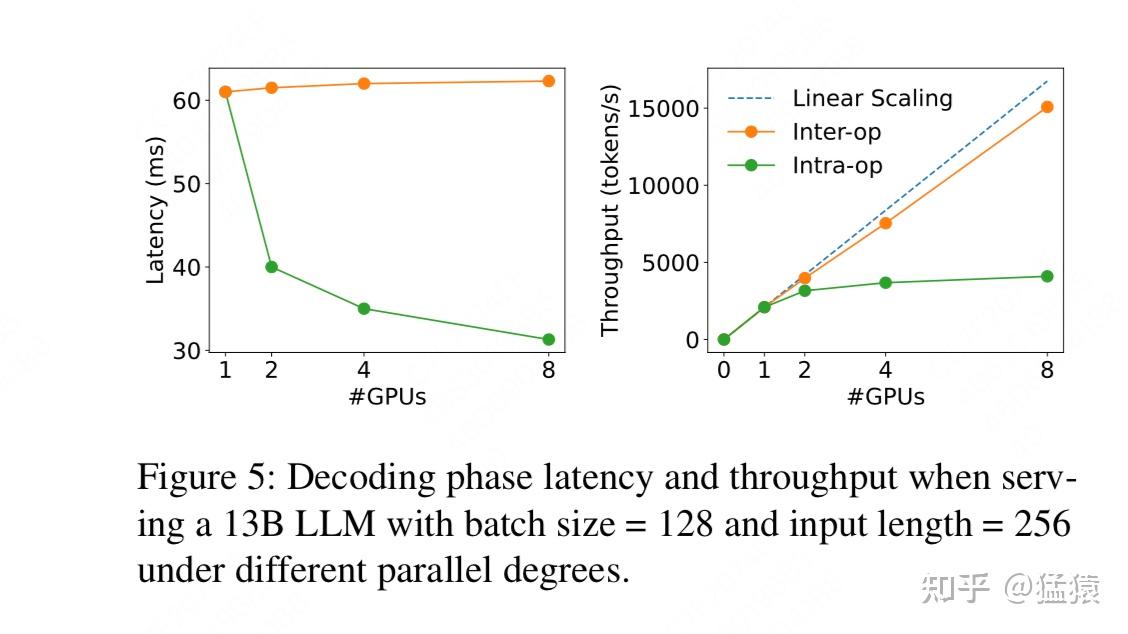
(2)decode阶段的并行策略
这里DistServe不再额外建模了,
但是它从另外一个角度做了模拟实验的结果
:
latency:模型处理完一个请求的耗时
throughput:单位时间内模型能处理的token数量
可以发现,对于decode阶段,随着gpu数量的增加,如果采用pp的方式,能产生更高的吞吐量(理由上面讲过,PP对batch的处理时流水线式的);但是如果用tp,则能产生更低的延迟(即虽然单位时间内处理的tokens数量有限,但是处理单个请求的时间变快了)。
四、实操:代码实践中的prefill/decode并行策略
在上述的讲解中,我们通过实验的方式,比较直观感受到prefill和decode阶段对于不同并行策略的倾向性。我们还首次尝试通过数学建模的方式,来拟合在不同并行策略下系统的性能曲线
(不过正如前文所说,我们初次尝试的这个数学模型具有一些强假设,使得它不适合用在实践中。因此在实践中我们可能要考虑别的建模方式,我们马上来谈着点)。
在本节中,我们来具体看DistServe在代码实践中是如何为prefill和decode阶段分配最佳并行策略的
。
在开始讲解之前,我们
先明确实操中DistServe的整体优化思路
:
(1
)对prefill和decode分别做goodput最大化,也就是对他们分别寻找最佳的并行策略(确定一个实例/一个模型副本要怎么分割)
(2)
根据系统中的流量大小确定prefill/decode下一共要部署多少个实例
,然后按照(1)中确定的并行方式做实例部署
在DistServe中,管这样的策略叫placement。
接下来,
我们再来看两种不同的硬件场景
:
场景1:node间带宽十分高,这样我们可以忽略KV cache的传输时间
。我们使用
algorithm1
来寻找在这样的场景下对单个prefill/decode实例的最佳并行策略。值得说明的是,单node推理也属于该场景
场景2:node间的带宽并不高,不能忽略KV cache的传输时间。这种情况下,我们尽量把prefill和decode实例对应的模型层分在同一个node中
(也就是prefill和decode的pp维度必须相同)。这种是实践中更普遍的场景。
【本节根据论文伪代码及DistServe开源代码库撰写而成。
https://github.com/LLMServe/DistServe/tree/main/simdistserve
】
4.1 伪代码:寻找最佳并行策略
左图对应场景1,右图对应场景2。
(1)场景1
N:表示一个prefill/decode实例最多能占用多少台node
M:表示一个node最多有多少张卡
C:集群中GPU的存储总量
W:系统的负载情况
。这个指标和模型类型、input_length等指标密切相关。在3.3节做排队论建模中,我们曾假设模型处理单个请求的时间是一致的(这也意味着我们假设所有请求的input_length长度一样),这在现实中是不可能的。在现实生活中,你的这个系统可能部署了不同的模型,而用户对每个模型的使用有倾向性,同时在每个模型中,用户传入的input_length也是不同的,所以我们可能很难对系统的负载情况建模。但是我们可以通过模拟实验的方式,先收集一段时间的用户真实数据,然后用一个模型计算出用户真实请求服从的分布。接下来我们只需要从这个分布中做采样,就可以采用出一批数据帮助我们做并行策略的profiling了。我们可以把这批采样出来的数据理解成是系统的负载W。真实代码中的load_workload就在做这件事。
R: traffic rate
,即单位时间内到达这个系统的请求数量。
best_plm: 最佳策略
,等于(n, config_p, m, config_d)
config_p
:
prefill阶段最佳的并行方式
(每个config_p装一套完整的模型,我们称为一个prefill实例)
config_d
:
decode阶段最佳的并行方式
(每个config_d装一套完整的模型,我们称为一个decode实例)
n
: 理解为prefill阶段的dp值,即要部署多少个prefill实例
m
:理解为decode阶段的dp值,即要部署多少个decode实例
了解了这些指标,看懂算法1就很容易了。
整体采用网格式搜索的方法,分别对prefill和decode找到满足最大goodput(这个指标表示满足认为设定的SLO值的最大rate值,rate值是单位时间内到达这个实例上的请求数量)。
这里我们只额外介绍一个有趣的函数simu_prefill。
我们以prefill阶段为例,这个函数的输入是当前我们搜索到的一个并行策略,以及模拟出来的负载W。
在DistServe的代码实践中,它是用一个“二分搜索”的方法来找到这个goodput值的,我相信很多朋友一定有所疑惑:欸,为什么找goodput值要用二分搜索的办法?
我们先来想一下,
当我们决定采用simu_prefill时,有哪些数据是明确的
:
TTFT SLO
:这是你认为设定的指标,即你认为系统要达到这个指标才算合格,因此它是确定的,它和算法无关。
并行策略G
负载W
:我们前面说过,这是我们根据历史数据拟合出来的输入数据的特征分布(input_length之类),然后我们用这个分布进行采样,得到了一批数据。接下来我们就要考虑把这批数据按照什么样的节奏发送到你的prefill实例上。
那这个“节奏”是指什么呢?我们再回想一下2.3实验结果中的那张图(还记得吗,我们就是通过这张图定义了goodput的含义的),
不难理解,这个节奏其实就是指发送rate,也就是goodput的备选值。
所以,goodput不是我们通过simu_prefill函数直接算出来的:
它首先是一串备选值(比如goodput = 5就意味着rate在0~5间都可以)
。
然后我们以不同的goodput(节奏)发送模拟的数据(负载)到prefill实例上,按照当前设定的并行策略实际运行一次系统做推理,得到P90 TTFT指标。
将P90 TTFT指标和我们的P90 TTFT SLO做对比,如果这个小于SLO,则意味着可以加大rate,反之同理。
那既然现在goodput是一串备选值,那么我们就可以使用二分法,根据P90 TTFT和SLO的比较结果,改变我们搜索的上下界,找到最终的goodput
(leetcode medium之魂燃起)
好,现在我们已经理清了simu_prefill的运作流程,到这一步为止,我们是通过模拟实验的方式找到goodput,进而确定最佳并行策略的。而实验的目的则是获取prefill阶段的TTFT指标。但是,正如前文所说,如果我们能找到一种更确切的建模方式,对TTFT进行建模,那么我们就可以拥有函数式的simulator,这样在后续就可以避免每次都跑模拟实验了。
再详细一点,我们可以先跑几次实验结果,然后用这个实验结果作为真值,对我们的数学模型中的参数进行拟合。关于这一点,我们放在4.2节中详细介绍。
(2)场景2
理解场景2伪代码的关键就是明白,在场景2下node间的带宽较低,因此KV cache的传输时间不能被忽略。所以我们需要让decode和prefill实例对应的模型层在同一个node里,这也意味着它们的pp维度必须一致。在这个基础上理解2的伪代码就不难啦(脊椎病犯了,实在是敲不动了)。
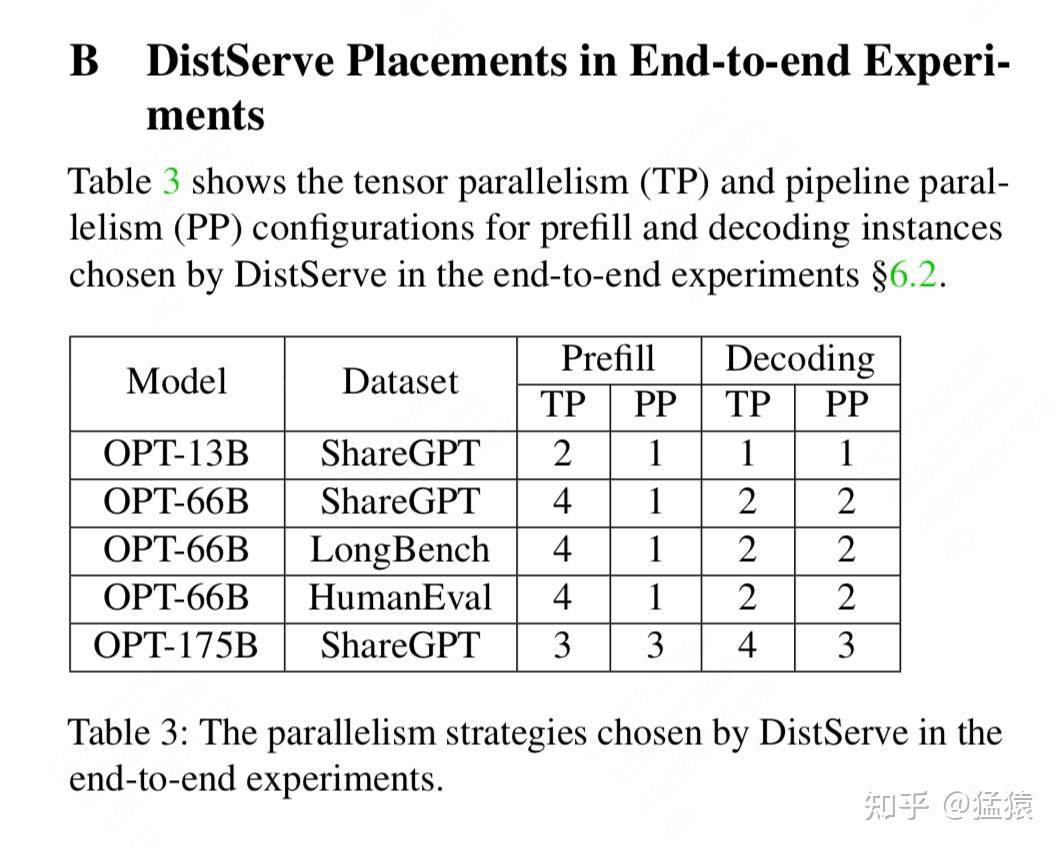
(3)并行策略结果
最后,让我们来看下DistServe实操中对于prefill和decode找到的最佳并行策略吧(注意,在175B的模型中,一个实例肯定是要跨机的)
4.2 实操中对TTFT和TPOT指标的建模
现在我们来回答4.1中遗留的问题:如果排队论的假设太过理想,那么在实操中,要怎么对TTFT和TPOT指标建模呢?
我们直接放出DistServe论文的appendix部分,这一部分写得非常非常好,短小精炼。但是对于对FLOPs,IO复杂度计算和flash attention不太熟悉的朋友,可能要花一些时间里了解。所以我把这一页都摘出来做说明。
首先我们明确一点
,在attention score的计算环节,我们使用了flashattention做特殊优化,因此它和别的环节的TTFT估计还是有一定差别的,所以我们需要把他们分开来说,我们以prefill阶段为例
,具体而言:
观察A.2中的table,它是去除attention score计算后剩余的GEMM矩阵
。shape of M/N分别表示这个GEMM计算的两个矩阵的维度。例如对于QKV linear,它指代的就是我们的输入数据通过Wq/Wk/Wv矩阵产出QKV值的过程。只是这里(t, h)表示我们把所有batch的数据拼接成一条,(h, 3h)表示我们把Wq/Wk/Wv矩阵拼成一个。这个table的其余列同理可推
根据这个table列举的GEMM计算,我们可得总FLOPs
(对这个计算方式不明确的朋友,可以参看3.1节中给的链接文章),这样就得到T1计算公式中括号里的那一坨
由于table中的GEMM计算都是compute-bound的,因此在考虑TTFT时我们可以忽略读取数据的时间
。这样,我们设因子C1表示计算单个FLOPs的耗时,那么table中的TTFT消耗就是T1所示。C1则是我们要拟合的模型参数。
观察T2,由于attention score的计算是memory-bound的
(尽管我们已经用flashattention做过了优化),所以我们不关心它的FLOPs,而关心它的IO复杂度(对这个计算有困扰的朋友依然可以参考3.1链接文章)。然后在这个基础上我们再设因子C2,表示单次读取的耗时。
综合T1和T2,建模出最终的prefill TTFT模型。对decode阶段也是同理,不再赘述。
原文地址:https://zhuanlan.zhihu.com/p/706761664
回复
使用道具
举报
提升卡
返回列表
发表回复
高级模式
B
Color
Image
Link
Quote
Code
Smilies
您需要登录后才可以回帖
登录
|
立即注册
本版积分规则
发表回复
回帖后跳转到最后一页
浏览过的版块
中标结果
病理检验
关闭
官方推荐
/3
AI助手<小桔子>来了!
欢迎来交流,可以回答IVD行业各类问题!
查看 »
IVD业界薪资调查(月薪/税前)
长期活动,投票后可见结果!看看咱们这个行业个人的前景如何。请热爱行业的桔友们积极参与!
查看 »
小桔灯网视频号开通了!
扫描二维码,关注视频号!
查看 »
返回顶部
快速回复
返回列表
客服中心
搜索
洽谈合作
关注微信
微信扫一扫关注本站公众号
个人中心
个人中心
登录或注册
业务合作
-
投稿通道
-
友链申请
-
手机版
-
联系我们
-
免责声明
-
返回首页
Copyright © 2008-2024
小桔灯网
(https://www.iivd.net) 版权所有 All Rights Reserved.
免责声明: 本网不承担任何由内容提供商提供的信息所引起的争议和法律责任。
Powered by
Discuz!
X3.5 技术支持:
宇翼科技
浙ICP备18026348号-2
浙公网安备33010802005999号
快速回复
返回顶部
返回列表

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 





 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 雷达卡
雷达卡 发表于 2025-1-30 11:47
发表于 2025-1-30 11:47


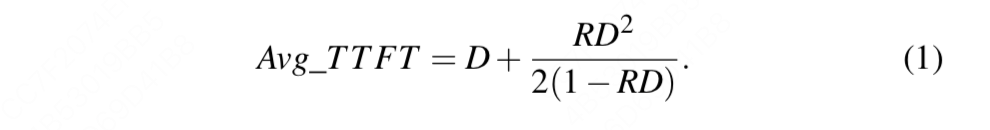
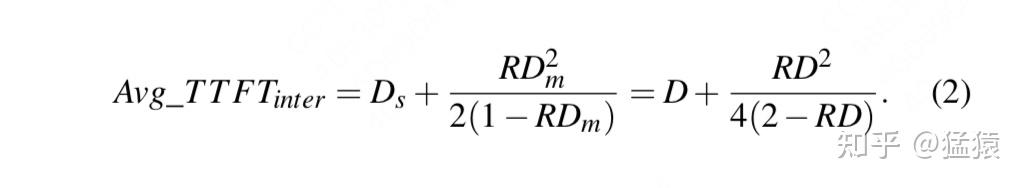
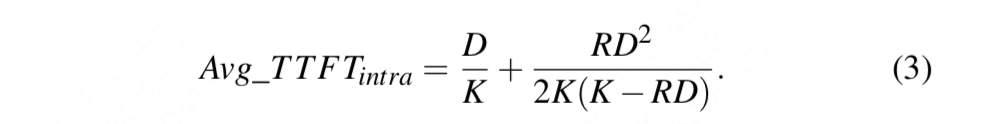


 提升卡
提升卡


