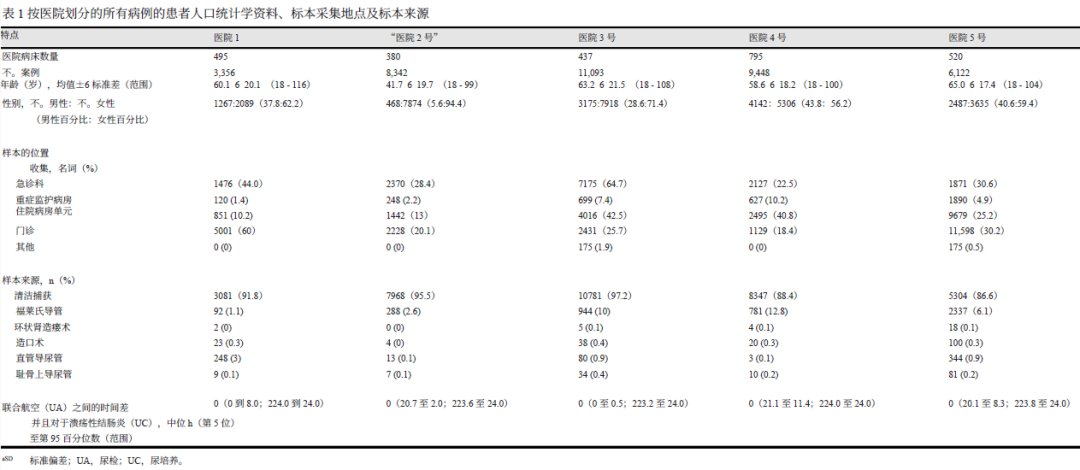
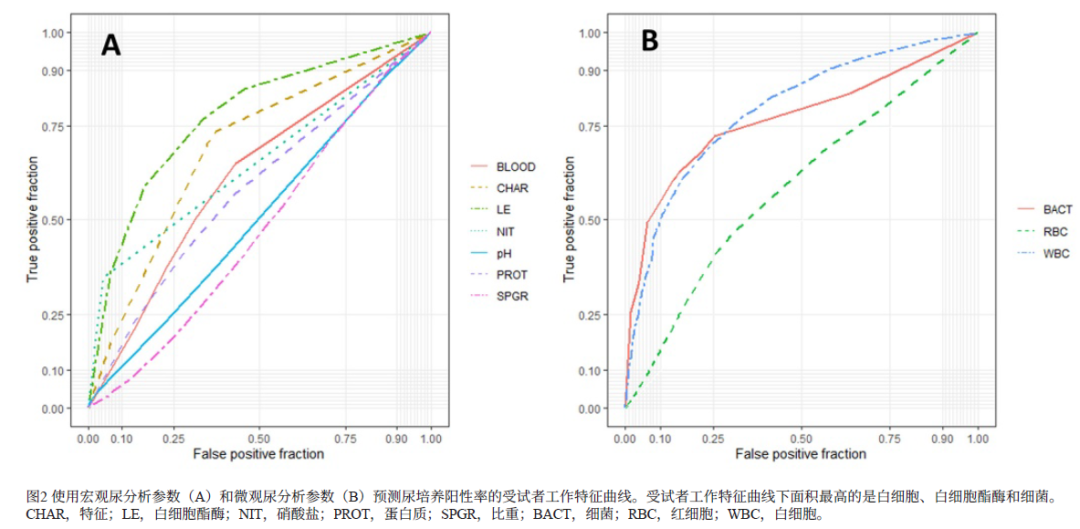
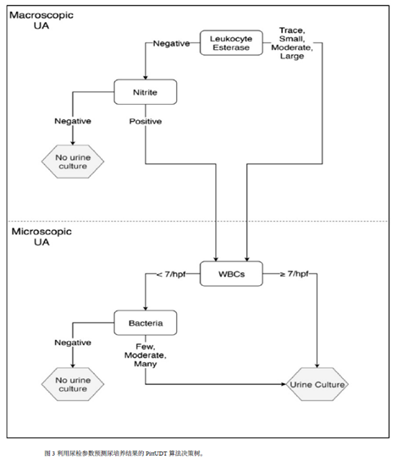
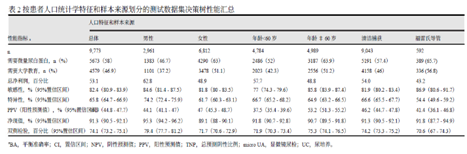
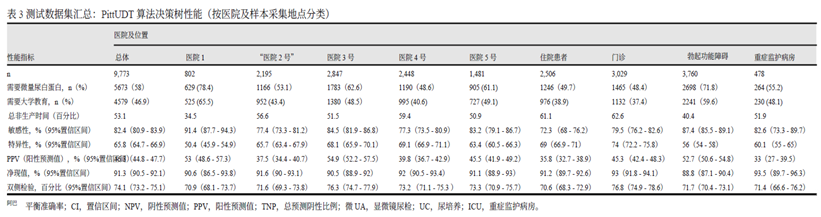
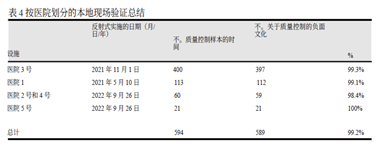
文献来源:
[1] Seheult JN, Stram MN, Contis L, et al. Development, Evaluation, and Multisite Deployment of a Machine Learning Decision Tree Algorithm To Optimize Urinalysis Parameters for Predicting Urine Culture Positivity. J Clin Microbiol. 2023;61%286%29:e0029123.

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 






 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 发表于 2025-5-25 13:33
发表于 2025-5-25 13:33