金桔
金币
威望
贡献
回帖0
精华
在线时间 小时
|
好吧,想当初我在生物信息学领域还是一个小白的时候,我也曾像题主这样寻求过网上资源。
首先回答软件方面,我也曾问过带我的博士:为什么想用一个软件,找半天都只有作者自己写的简略的英文readme,每次都要自己摸索老半天,都没有其他人分享的实际软件使用体验,像百度经验那样亲民就最好了。但事实上的确没有,因为生物信息学领域的各种软件更新太快,像blast系列,bowtie,tophat等软件,更新之后用法完全不一样,教程也得更新,像bwa,samtools等更新功能的,教程一般也没人及时更新,还不如自己看作者的readme,慢慢探索咯。生物信息学常见领域,如基因组,外显子组,转录组,等都有人专门收集软件集,比如:
最全面的转录组研究软件收集 还有
NGS数据比对工具持续收集 ,当然我这也是转载的国外的,一般来说,你想学软件,学会五六十个就差不多了,看看各个领域的关键词排名最高的综述一般都会讲的很全,任何一个软件说穿了就是准备好输入文件,配置好参数,然后解析它的输出文件。等你用到一定程度,很容易总结出规则,以后用任何软件都不需要再看中文的介绍了,直接就用,错了就Google,非常好使~!
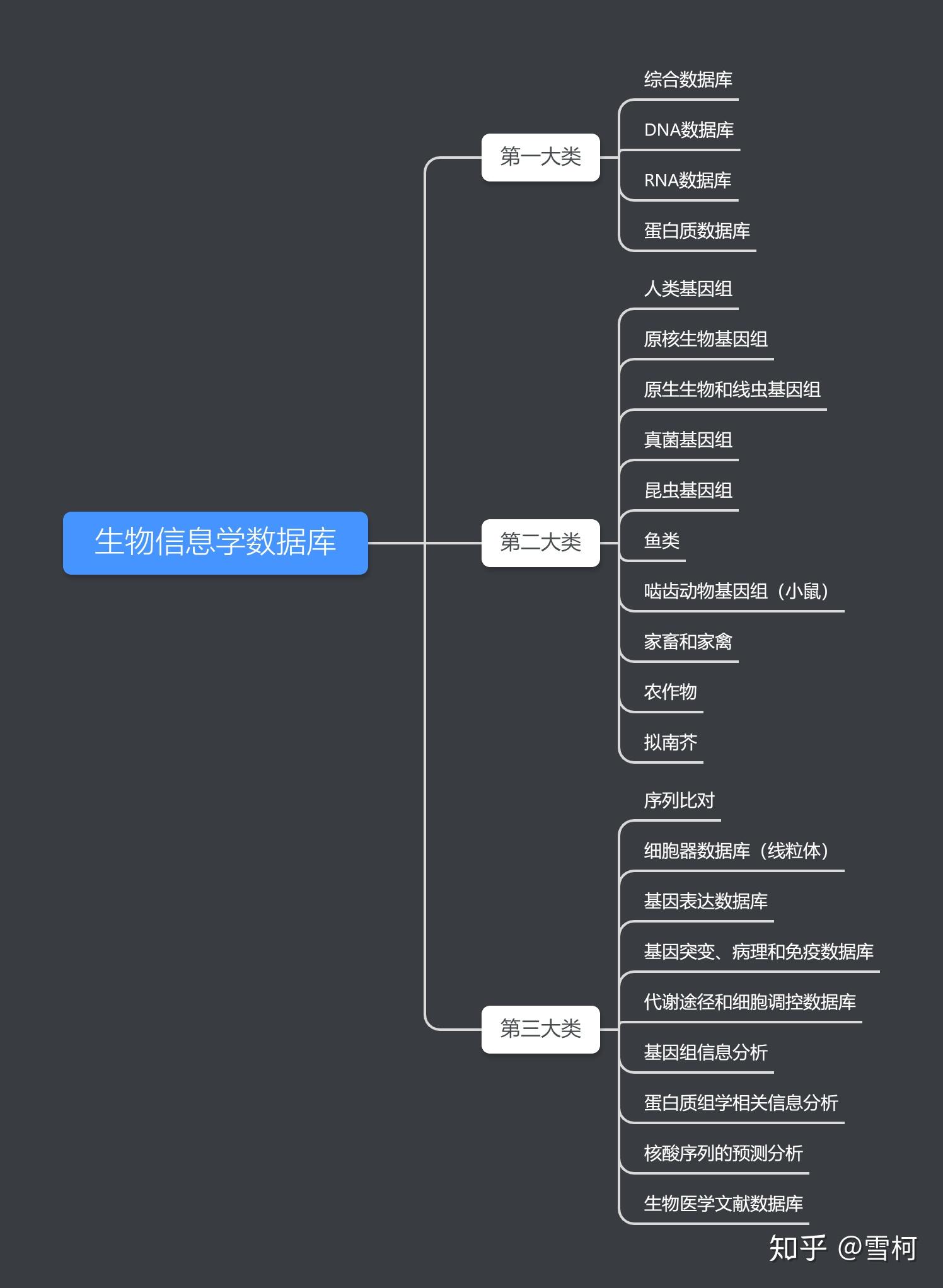
那么,再来说说数据库吧,这个实在是数不胜数了,
http://www.genecards.org/cgi-bin/carddisp.pl?gene=ALB 你进入这个页面,看到里面的所以链接都是一个数据库, 先不说基因的特征,仅仅是对一个基因进行命名就有一百多个国际组织搞些不同的名字,有的把TP53叫做7157(entrez ID),有的把它叫做ENSG00000141510(ensembl ID),其它好多ID我都叫不上名字,但是你记住出名的那几个就好了,所以你必须熟悉非常出名的那几个数据库,就是NCBI,ensembl,UCSC,其它的数据库主要是为了解释生物大分子的,也有跟疾病特异性数据库(比如:糖尿病),还有物种特异性数据库(大多数模式生物都有),但是除非你特定的要研究某个领域,否则你很难接触那么多数据库,一般也就是几个实验室自己在维护。
接下来是重点啦!
网上的学习资源:
先说点中文的,毕竟一般人也只有精力看这个了,首推就是北大的公开课啦(
MOOC课程_生物信息学: 导论与方法),然后你可以看看药明康德的陈巍学基因(
优酷网-中国第一视频网,提供视频播放,视频发布,视频搜索) 了解一些测序常识,接着你可以看看测序中国的一个公开课,最后你还可以关注很多生物信息学的微信公众号(这个非常重要,因为他们为了吸引关注,通常会放出很多干货!!!)
好了,接下来说重点,毕竟国内生物信息学起步很晚,所以网上资源肯定大多数英文的!
首推宾夕法尼亚州立大学-新一代测序技术数据分析-英语-生信课件加优酷视频
然后是德国自由大学生物信息学,课件可以自行下载
接着是美国明尼苏达大学生信课件,可以下载
还有NHGRI Current Topics in Genome Analysis 2014里面几百个ppt关于生物信息学研究热点
还有斯坦福大学-计算生物学-2011课程ppt,它专门课程专门把生物信息分成了6个topic,推荐了一百多篇文献阅读,均可下载!(
用wget批量下载需要认证的网页或者ftp站点里面的pdf文档),还有一个斯坦福大学-遗传生物信息课程-2009也很不错
还可以关注很多国外的生物信息学会议,影响很大的那种,一般都会公开ppt,都是很牛的导师在讲(
几个国外出名的跟生物信息学相关的会议)
也可以关注一些生物信息学出名的讲师(
推荐5个生物信息学领域的教授)
安德森癌症研究中心有一个芯片数据课程,也挺好的-anderson-基因芯片课程
还有二十多个生物信息学课程(都是各个大学的,比如MIT什么的,我自己都没看,就不推荐给你啦!)
晕,本来准备把我写的生物信息学资源持续收集通过有道云笔记分享给你的,结果!!!!!!!居然不小心给删除了,唉,真倒霉,几百个资源就那么没了!
反正我也是成长的过程中随便收集的,我相信你学习的过程中也能收集到很多好资料的,希望你也可以分享给后来者,让他们少走弯路!O(∩_∩)O谢谢 |
|

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 





 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 雷达卡
雷达卡 发表于 2025-5-30 17:37
发表于 2025-5-30 17:37


 提升卡
提升卡